New Azure Pipelines build with Code Coverage, CICD, and an organized package structure.
See Release Notes
Barrier Execution Mode, performance improvements, increased parameter coverage
Learn More
Explore the mind of a GAN trained on the Metropolitan Museum of Art's collected works. Then, find your creation in the MET's collection with reverse image search.

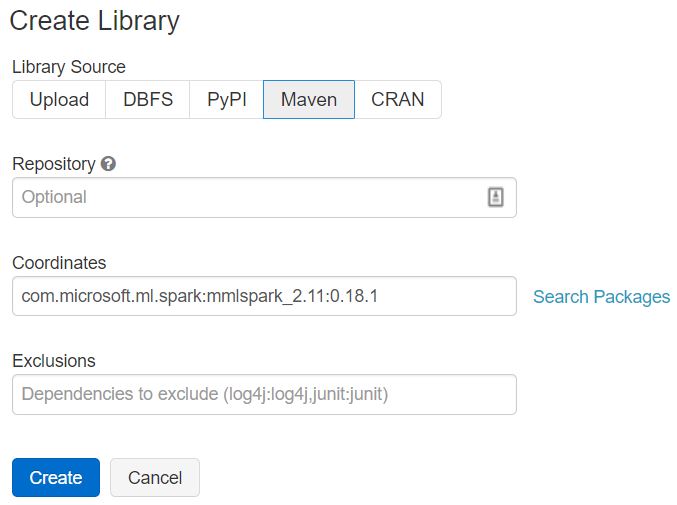
Leverage the Microsoft Cognitive Services at unprecedented scales in your existing SparkML pipelines
Read the Paper
Spark is well known for it's ability to switch between batch and streaming workloads by modifying a single line. We push this concept even further and enable distributed web services with the same API as batch and streaming workloads.
MMLSpark adds GPU enabled gradient boosted machines from the popular framework LightGBM. Users can mix and match frameworks in a single distributed environment and API.

Vowpal Wabbit on Spark enables new classes of workloads in scalable and performant text analytics

MMLSpark provides powerful and idiomatic tools to communicate with any HTTP endpoint service using Spark. Users can now use Spark as a elastic micro-service orchestrator.

Understand any image classifier with a distributed implementation of Local Interpretable Model Agnostic Explanations (LIME).

MMLSpark integrates the distributed computing framework Apache Spark with the flexible deep learning framework CNTK. Enabling deep learning at unprecedented scales.
Read the Paper
MMLSpark's API spans Scala, Python, Java, and R so you can integrate with any ecosystem.